Kafka vs RabbitMQ at first sight
There is a big hype with message queuing nowadays. To send updates to vary services, to add tasks to background process, to store statistics or logs: there are just a few examples of its usage.
There are two most popular solutions on market: Kafka and RabbitMQ. Yep, there are also ActiveMQ and Nats, but I met only one project with their usage in my experience.
Let’s dive a little to find the best cases for each solution.
The main idea
Kafka
is a very clear and simple instrument, that allows you to store messages in very fast manner. The only one duty of kafka is to store received message to the disk.
So the first conclusion – you must implement all the other message processing logic on the client side. Kafka is just a tool that saves messages to the disk and sends it to the client from the right place if it is needed (after request). That’s why Kafka is very very very fast.
Also Kafka is great from horizontal scaling pov. We just need to add new nodes and make partitions rebalance to the new nodes. That’s all.
Rabbitmq
The official site tells us that it’s the most popular message queuing system on the market. Yet Rabbitmq is not as simple as kafka.
There are lots of internal tools in rabbitmq:
- exchanges with routing
- plugins for delayed messages
- deadletters and other stuff
Rabbit is monitoring for all messages. It deletes message after consumer response about its delivery. If consumer is dead in the middle rabbit will return the message to the queue. So it’s just a great “swiss knife” when you need to send a mass of messages between services. The price is – productivity.
Rabbit is trying to make a lot of work, so it obviously needs a bigger resources consumption.
Conclusion:
- If you need transfer messages between the services and amount is not huge – you should prefer RabbitMQ.
- If your task is to save a lots of events very quickly (client metrics, logs, analytics) – Kafka is your choice.
Tests comparing of kafka vs rabbitmq
I took a simple Golang application, that receives json messages via http and saves it to Kafka or to Rabbitmq.
App server is listening to port 80. Kafka and Rabbit servers are behind him. Also kafka needs Zookeeper so we have it on the needed hosts. There are no nginx or any load balancer.
The next task is:
to launch loader.io free tests with 1,5 kb json file to be sended. 10k requests per second to our golang app and after collect error amount, medium response time and other metrics.
3 hosts (app server and 2 rabbit/kafka nodes) were launched on DigitalOcean in Amsterdam, 20$ per month for each one. 2 CPU, 4 GB RAM, 80 GB SSD. Very light-weighted instances for 10 000 rps tests. The total cost is 60$ per month.
Sure the could also be a load balancer with ssl termination or other cool things, but we really do not need it for our tests. We are not making nginx test, we are trying to stress brokers, right?
Test 1. Kafka. 10 000 RPS. Wait For All. Sync Producer
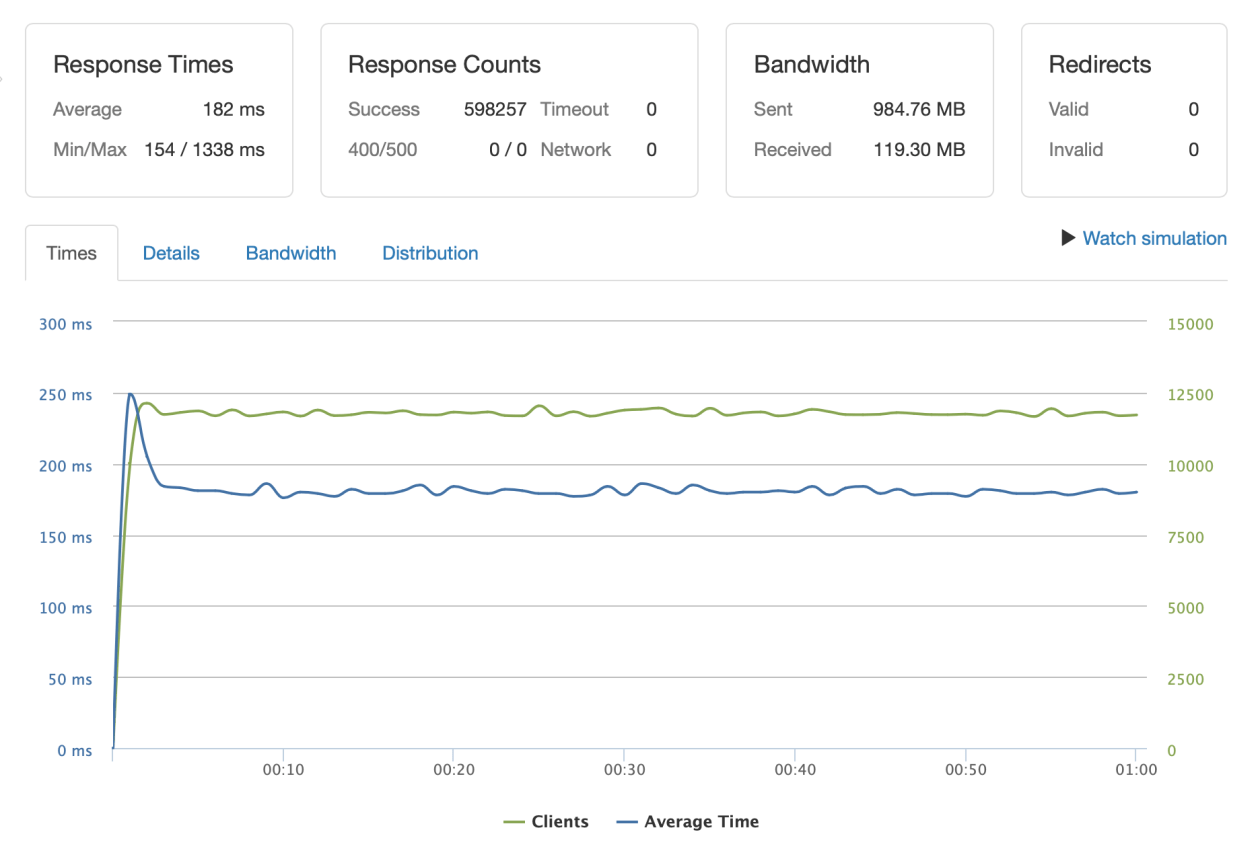
Here is a very stable response time (182 ms), especially for the fact loader.io is staying in the USA while the hosts are in Europe physically. Also 100% success is not a bad result. The initial peak is come from connection establish between kafka and our application service.
The main idea from the test – message producer is synchronized. It will wait for the moment of all messages written (config.Producer.RequiredAcks = sarama.WaitForAll). So if we respond client with status 200 it means we obviously not lost his message.
The graph of Kafka internal monitoring:
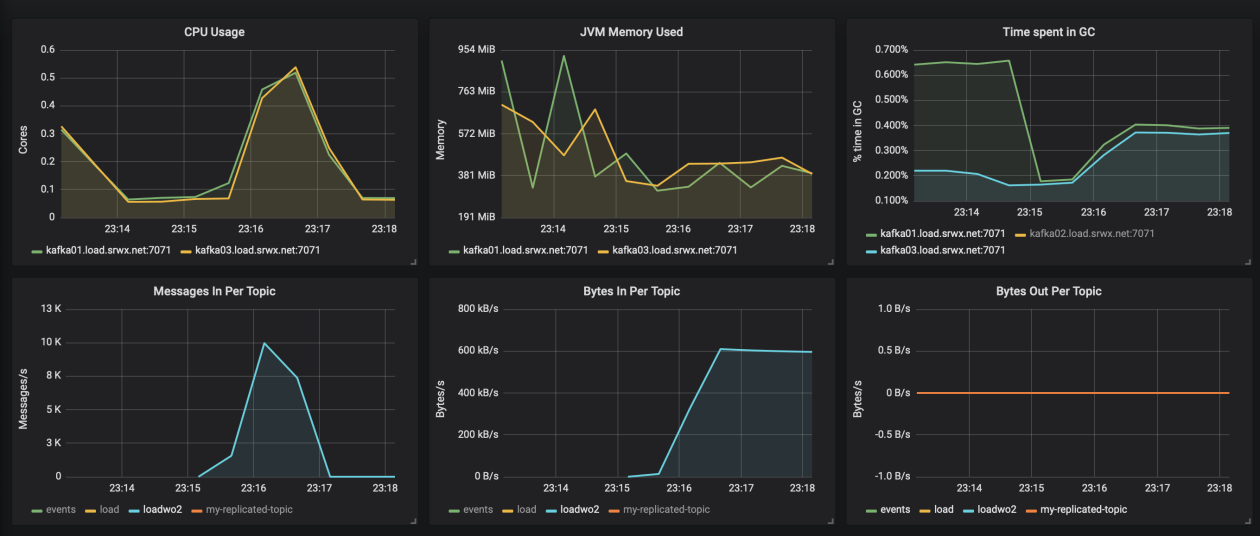
Eagle eye can find that the bandwidth is different from the loader.io value (1 gb / 1 min ~ 16 mb/sec) — it’s just because our service are sending compressed messages into the kafka.
The last but not least – this architectural scheme is great for horizontal scaling on any level. We can add services nodes, we can add kafka nodes: voila and we are ready to process 500 000 mps. To reduce the latency we can launch few go app + kafka installation instances in different time zones and add routing via cloudflare load balancers.
Test 2. RabbitMQ. 10 000 RPS. High Available Cluster. ASync Producer
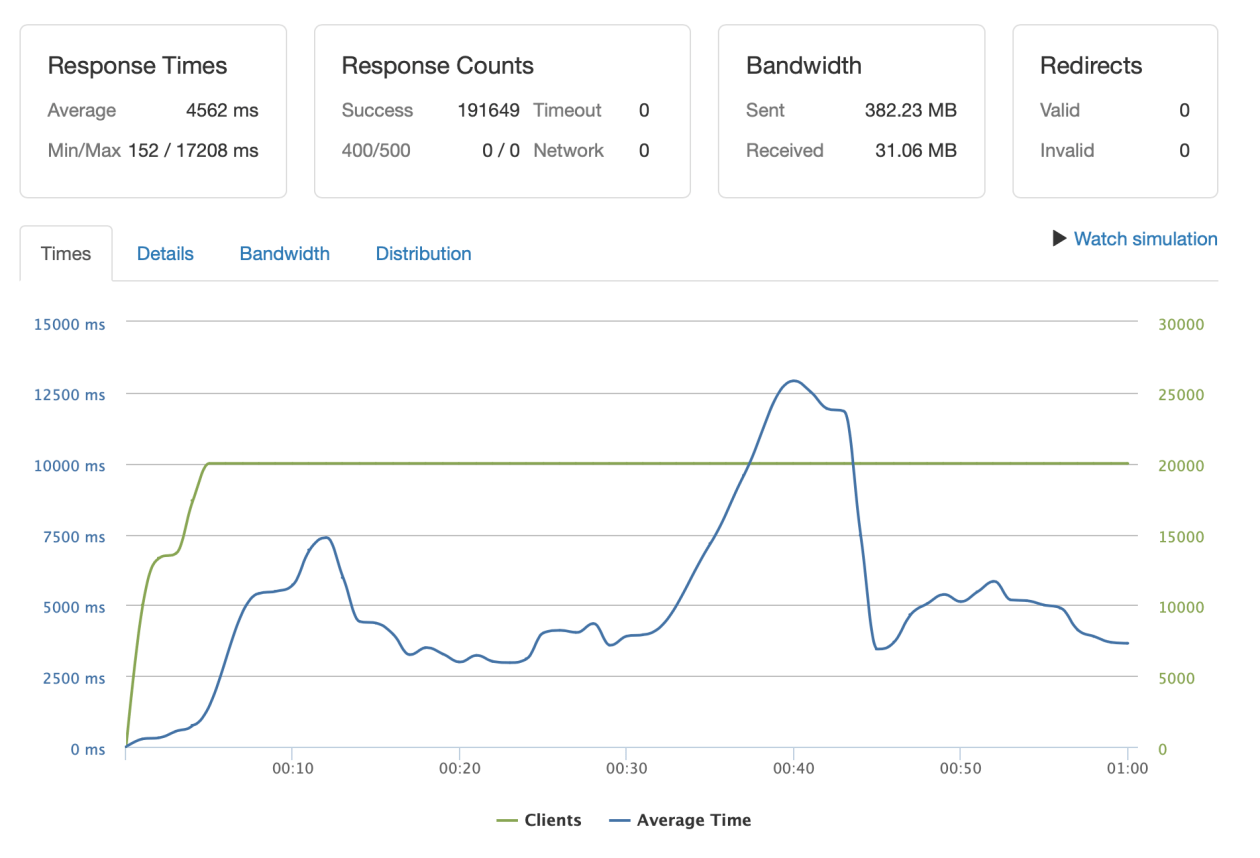
Rabbit is not so great in such pressure. First of all let’s talk about the cluster settings. There are nothing specific: 2 hosts in one cluster totally synchronizing the queue. Everything was done according to the official guides.
The worst result here is the medium response time ~ 4.5 s. It’s too much for the service which is planned to wait for a large amount of incoming messages.
On the other hand – in HA mode Rabbit makes 4k/sec even on such a light-weighted servers.
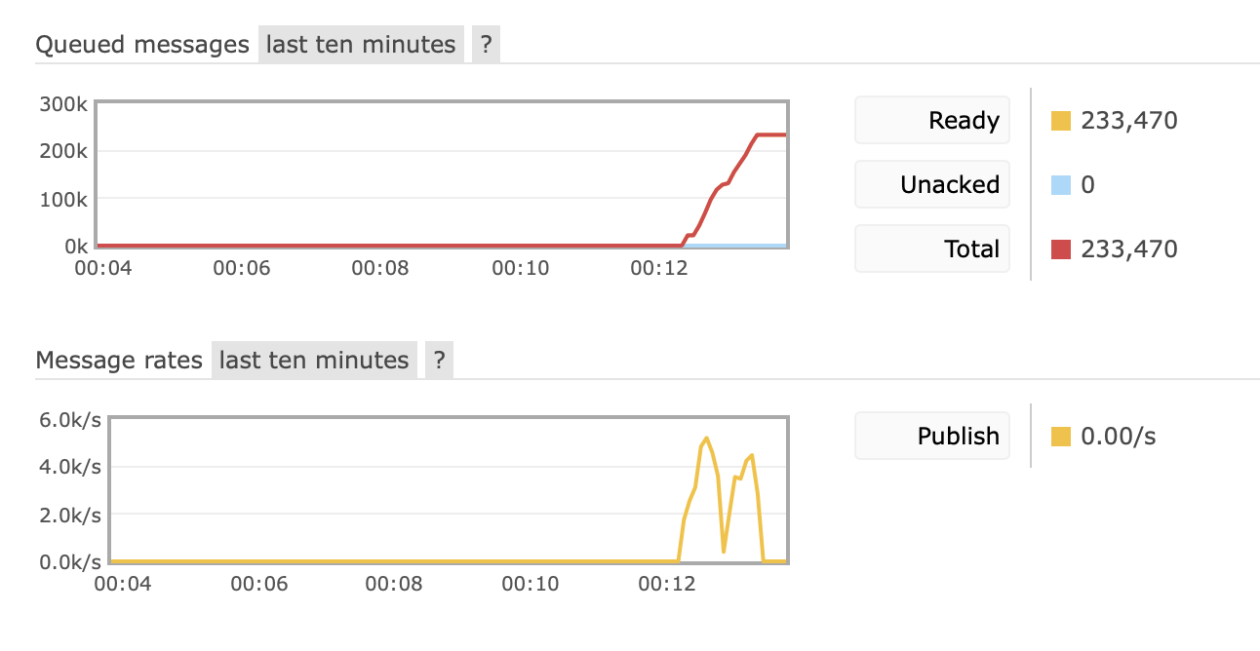
Specially want to mention that Golang amqp library is asynchronous by default. So when we are responding with status 200 to the client, it is not guaranteed that the message will be saved. I was a bit lazy to work about it, especially because the asynchronous query should be theoretically transferred earlier. So we can even talk about a little allowance to Rabbit.
Теsт 3. RabbitMQ. 10 000 RPS. Single Node. ASync Producer

The truth is Rabbit spends a lot of resources for node to node synchronisation process. So I made last test with run Rabbit in non-cluster single node mode. We will store the message into this single node.
Not a surprise – the response time reduced to 1,5 sec that is much better. Also the message per second rate is close to Kafka’s one.

Conclusion and useful links
This is not a very big exploration. If you want to deep dive into the queueing world I strongly recommend you following links::
NOTE: if you need to receive 10k / 100k of messages per second you MUST use kafka. The price of the game is 60$ per month for 10k rps. You would be happy with it.